Webinar Recap: Protecting Content in the Age of Generative AI

Earlier this week, we hosted the webinar, “Protecting Content in the Age of Generative AI,” in which our CEO and Co-Founder, Dr. Hirsh Pithadia, discussed the challenges content creators and platforms face in protecting their content as generative AI technologies advance. One of the key issues highlighted is how generative AI models rely heavily on vast datasets for training or context enrichment. Much of this data is gathered through scraping, raising legal and practical questions about the use of publicly accessible content. The webinar’s focus was on active and passive protective measures.
Active Measures
These involve direct interventions designed to prevent or disrupt unauthorised access or use of data by AI systems:
Adversarial Techniques: Methods like Nightshade introduce subtle, imperceptible changes to data, corrupting AI model training. While effective, these techniques require regular updates to counter evolving AI training strategies and may inadvertently degrade legitimate data use.
Bot Detection and Blocking: Tools that detect, block, and monitor bots attempting to crawl content. These rely on identifying unusual crawling patterns or using forensic techniques to detect bot signatures. However, challenges persist as many bots ignore politeness rules or adapt to evade detection. During the webinar, we demo-ed Valyu AI Bot Analytics Dashboard, showcasing real-time bot detection and monitoring capabilities.
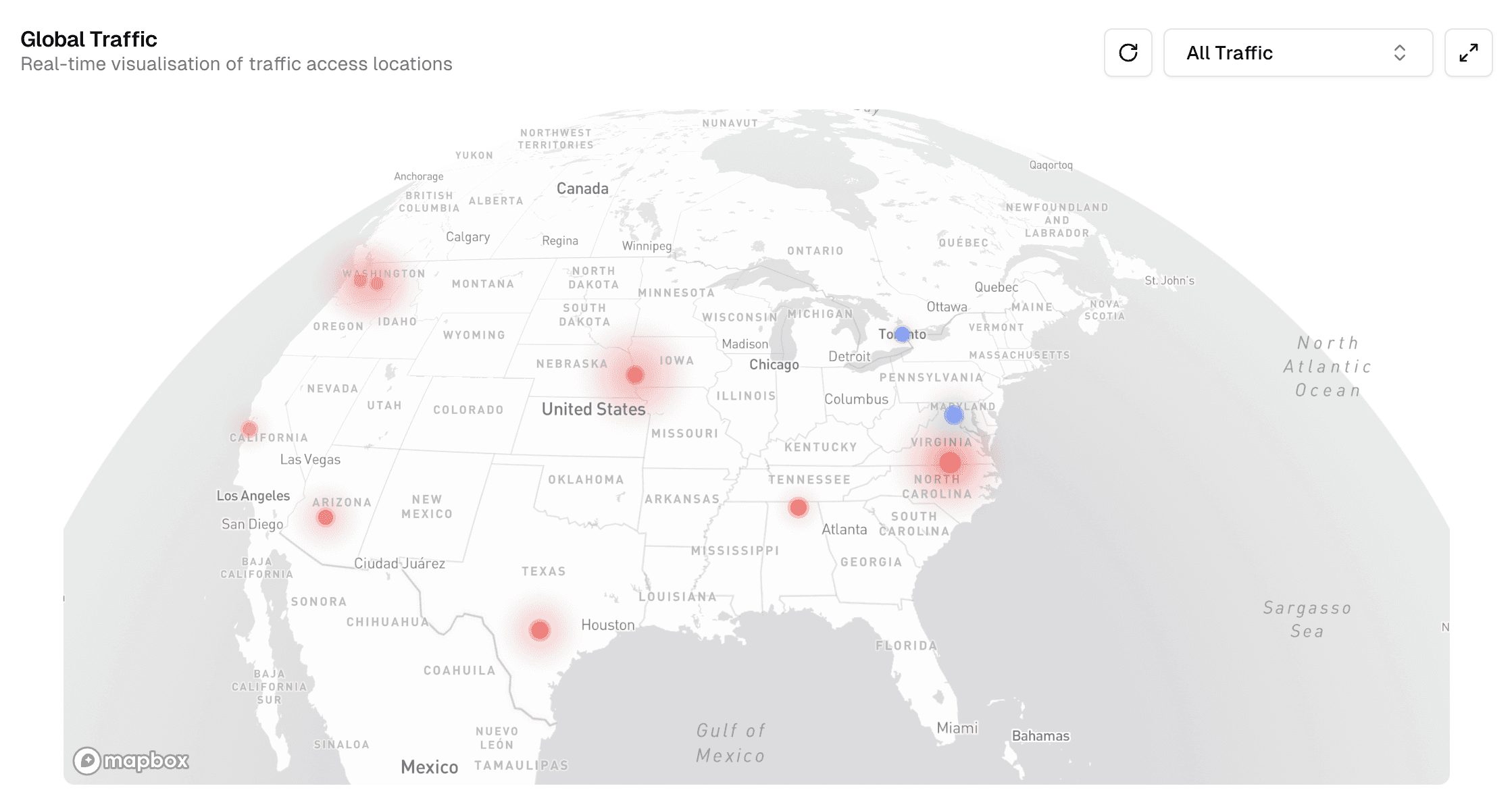
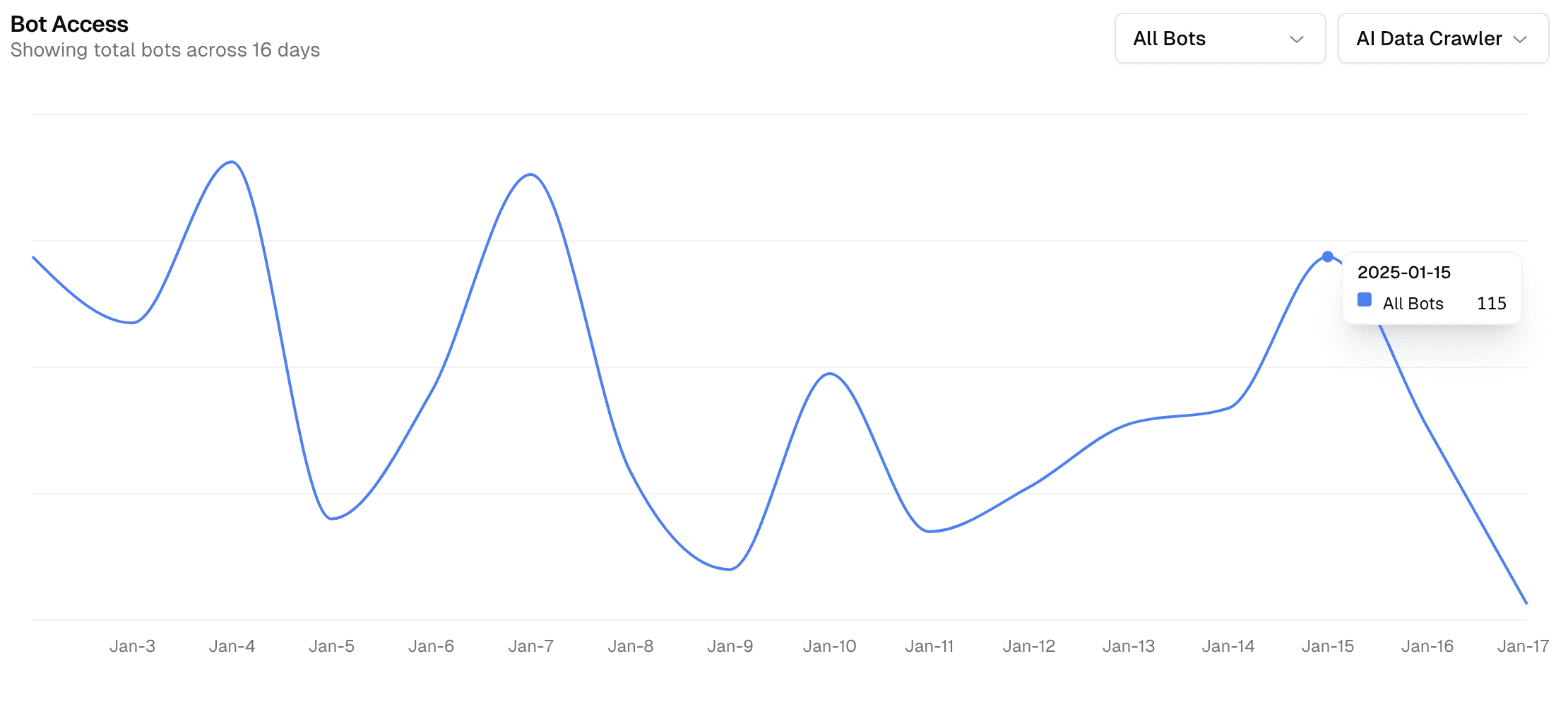
Valyu AI Bot Analytics showing bots (red dots) and real users (blue dots) from various locations in the US visiting a website. Source: Valyu.
Passive Measures
Unlike active approaches, passive measures indirectly protect content by signalling usage preferences, relying on AI developers or systems to act in compliance. The foundation of these measures is consent and how it is communicated, which forms the basis for opt-in or opt-out systems.
Opt-in Systems: Data can only be used if explicit permission is granted by the rights holder. This approach requires proactive action from rights holders, offering stronger control but at the cost of scalability. For example, a publisher may explicitly grant access to their dataset for specific use cases.
Opt-out Systems: Data is considered usable unless explicitly restricted by the rights holder. While simpler to implement, this method assumes an infrastructure capable of compliance and monitoring. Current opt-out methods include Robots Exclusion (robots.txt), metadata-level instructions, and Do-Not-Train registries. However, robots.txt, originally designed for managing bot overload and traffic, is not suitable for managing consent.
Here at Valyu we are working on some of these hard problems- how do we allow AI developers to access high quality data for training and context enrichment whilst supporting rights holders. Active and Passive measures offer rights holders the ability to control the consumption of their content by AI developers.
Watch the recording of the webinar “Protecting Content in the Age of Generative AI” below: