Promises and Pitfalls of Synthetic Data and Why Provenance is Necessary

While synthetic data offers immense potential for AI model training, its effective use hinges on rigorous quality control measures. Tools and strategies that provide deep insights into the data's origins and characteristics are essential for building reliable and effective AI systems. By leveraging technologies like the Valyu Exchange Provenance Tool, organisations can navigate the complexities of synthetic data management, ensuring their AI systems are both accurate and trustworthy.
Why is Data Provenance Necessary… Promises and Pitfalls of Synthetic Data?
Recent advancements in artificial intelligence have led to increased experimentation with synthetic data, particularly by leading companies in the large language model (LLM) sector like OpenAI and Cohere. The push towards synthetic data stems from its cost-effectiveness and ease of generation compared to the traditional method of scraping and processing web data. As high-quality data from the web becomes scarcer and more costly, synthetic data is emerging as a viable alternative to increase the liquidity of training data for these models.
The Risks of Synthetic Data
However, the use of synthetic data for model training comes with several potential pitfalls that must be carefully addressed:
Model Collapse
There are several pitfalls when training models on synthetic data only. A significant concern highlighted in recent studies is the risk of model collapse—a phenomenon where models recursively generate and then train on synthetic data. This is documented in several research papers 1, 2, and 3, which point out that both LLMs and other architectures, such as diffusion models, tend to show diminishing performance when trained across multiple generations of synthetic data. The cause of the model collapse is the iterative divergence from the original data distribution causing the final distribution which does not resemble the original distribution. This leads to increasing perplexity, a measure of the deviation of a dataset from its original, across generations. Furthermore, fine-tuning strategies may not be sufficient to address the fundamental flaws that arise, essentially reducing the model's intrinsic reasoning capabilities.
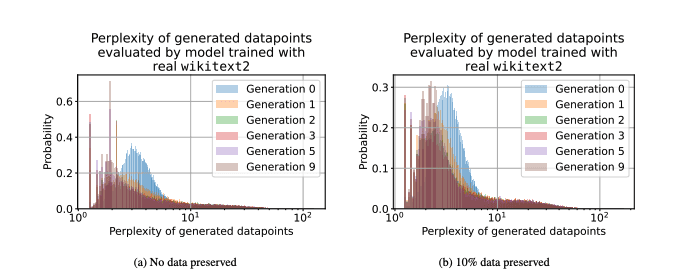
Data perplexity distribution across synthetic dataset generations for purely synthetic datasets and datasets where only 10% of the original data is preserved. Source: arXiv.
Data Quality Issues
Another critical issue is the quality of the synthetic data itself. The adage "Garbage in, garbage out" holds true in the context of machine learning, emphasising the direct impact of training data quality on model outputs. Poorly curated synthetic data, such as those with formatting errors, duplication, or generated through flawed processes, can poison the model inadvertently. For instance, responses from the model Grok suggest potential training on data generated by OpenAI models, illustrating the practical implications of such oversights.

Grok regurgitating OpenAI responses in its responses shown by X (Twitter) user Jax Winterbourne. Source: X.
As text and image generation models become more widespread, their outputs increasingly populate the web. This proliferation poses a risk for any datasets curated post-2022, as they may inadvertently include low-quality data points produced by these generative models. To mitigate this, companies must implement rigorous data hygiene practices to ensure the integrity of their training and fine-tuning datasets and prevent the contamination of their models with inferior data.
Mitigating Risks and Ensuring Data Quality
To mitigate the risks associated with synthetic data, companies must implement rigorous data hygiene practices to ensure the integrity of their training and fine-tuning datasets:
Manual Data Review
A few solutions exist to avoid the pitfalls which come with synthetic data. The obvious solution is to manually review the quality of every data point to ensure the quality of data. There are several issues with this approach. First, it is expensive and time-consuming and removes one of the key benefits of manually curating data. Another issue is that improperly synthesised data despite on the surface being high quality may not preserve the underlying context of the data which will cause data distribution divergence. This divergence often results in datasets that fail to accurately reflect real-world conditions or maintain the consistency necessary for training robust AI models. Hence, a lot of time and effort must be taken to properly review these datasets.
Data Provenance Tracking
A more robust solution is tracking the provenance of the dataset. Understanding the origin of data—including the models and original datasets used in its creation—allows users to assess potential quality more accurately. The Valyu Exchange Provenance Tool exemplifies this technology by enabling users to trace the lineage of their data comprehensively. Our tool not only tracks the sources but also the derivative models and datasets, providing a clear view of the entire provenance chain. Such transparency is invaluable in judging the data's quality and ensuring its alignment with specific model requirements.
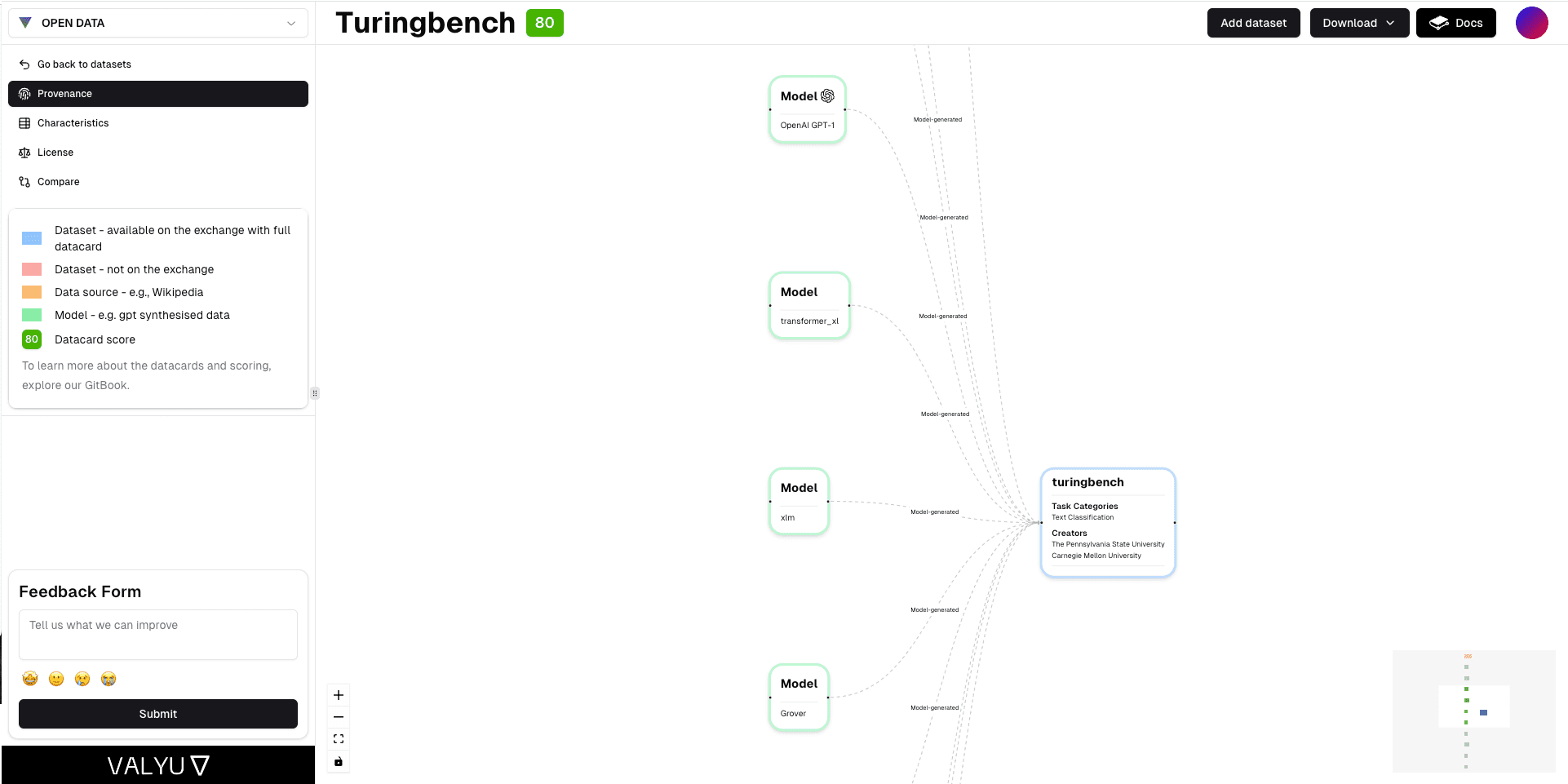
The Valyu Exchange provenance tool with an example dataset showing the sources and models used to construct the dataset. Source: Valyu Exchange.
Automated Data Synthesis and Provenance Integration
Our data synthesis tool also automatically integrates into the provenance tool allowing you to automate this process, offering a seamless way to maintain oversight over data generation and usage. This integration is particularly crucial for managing compliance with licensing agreements. For instance, the provenance tool can automatically detect and alert users to potential license conflicts, such as those arising from policies that restrict the use of certain models for data generation. For example, OpenAI’s policy disallows users from using their models to generate data. This license conflict is automatically tracked by our exchange.
Data Quality Evaluation
Further enhancing data integrity, tools like the Datapoint Metric Checker allow users to evaluate their datasets against other datasets. This comparison is vital for confirming the data quality and can help pre-empt the training of models on inadequate or flawed data.
Conclusion
While synthetic data offers immense potential, its effective use in AI development hinges on rigorous quality control measures. Tools and strategies that provide deep insights into the data’s origins and characteristics are essential for building reliable, effective AI systems. With Valyu, organisations can navigate the complexities of synthetic data management, ensuring their AI systems are both accurate and trustworthy.
—-
Cover Image by Google DeepMind from Pexels.