10 Key Terms in AI and Training Data

The rapid adoption of artificial intelligence (AI) tools like ChatGPT has ignited curiosity, especially among newcomers to the field. As AI continues to evolve, it introduces a range of technical terms that can often feel daunting. In this blog post, we've simplified the 10 key terms related to AI and Training Data to help you better understand how AI tools and systems are built and operate.
10 Key Terms in AI and Training Data:
1. Large Language Models (LLMs)
Large Language Models (LLMs) are foundational to the recent AI boom, powering the biggest models like ChatGPT, Claude, and Gemini, among others. In essence, LLMs are sophisticated predictors of the next word in a sequence, enabling them to generate coherent and contextually appropriate text. These models have been trained on extensive datasets comprising both publicly available and proprietary data, allowing them to perform a wide variety of tasks with impressive accuracy. For example, when you ask an LLM, "How do I make pizza?" the model is not recalling a specific recipe from memory but rather predicting the most likely sequence of words to follow, such as "You first have to…".
2. Training
Training an AI model involves giving it vasts amounts of relevant training data for the task you want it to be good at. This is crucial because it helps the AI model learn patterns, generalise to new data, and improve accuracy. There are 2 types of training, pre-training and post-training:
Pre-Training
In pre-training, the model is exposed to vast amounts of general data (such as text from books, websites, or other sources). This phase helps the model learn broad language patterns and build a foundational understanding of how to process language. Pre-training doesn’t necessarily teach the model about specific tasks—it’s more about giving it general knowledge.
Post-Training (Fine-Tuning)
After pre-training, the model is fine-tuned for specific tasks using smaller, more focused datasets. For example, a pre-trained model might be fine-tuned on customer service transcripts to help it become particularly adept at answering customer queries. Fine-tuning sharpens the model’s skills for particular applications, making it more accurate for domain-specific tasks.
3. Training Data
Training data is the set of data used to teach AI models how to perform certain tasks. For example, for image generation models, the training data may consist of large collections of labeled images—each image paired with descriptive text or tags. Besides images, there are several other types of training data that are crucial for developing AI models such as text, audio, video, and time-series data to name a few. Training data is paramount for teaching AI models how to think, understand, and perform tasks — essentially the backbone of the system’s capabilities.
4. High-Quality Data
AI models need training data because it serves as the foundation for learning and making prediction. However, AI models perform better on high quality data. What does this mean? While the definition of high-quality data varies significantly across different intended tasks and dataset modalities, several high-level characteristics generally apply:
Relevance
The data should be pertinent to the specific problem the model is addressing, e.g., an AI model trained to recognise art images must be trained on art images, not general photographs.
Diversity
A broad range of scenarios and variations related to the task such as different conditions, contexts, and examples. A diverse dataset helps the model generalise well by representing a wider spectrum of demographics and contexts.
Accuracy
The data must be accurate and correctly labelled. Errors in labels or annotations can mislead the model and degrade its performance.
Timeliness
The data used should be up-to-date and reflect current trends, conditions, and contexts. Outdated data may not accurately represent the present state of the problem, leading to poor model performance in real-world applications.
5. One-Boxing
Have you noticed that most browsers are beginning to integrate AI summaries or overviews at the top of search results? For example, one may ask “how to reduce anxiety”, and instead of searching through different articles on the results page of a search engine, the AI overview gives back a quick summary of the topic at the top of the search engine results. This is known as one-boxing, and is a big win for quicker knowledge retrieval, reducing the friction it takes to get our questions answered. However, publishers and content creators are increasingly concerned that this will significantly reduce traffic to their websites. Valyu solves this problem by providing publishers with a new form of content distribution tailored for the AI-driven internet. Through the Valyu Platform, publishers can access an ecosystem of AI developers who need content for training and fine-tuning machine learning models and applications. This allows publishers to increase revenue from their copyrighted works while retaining full control.
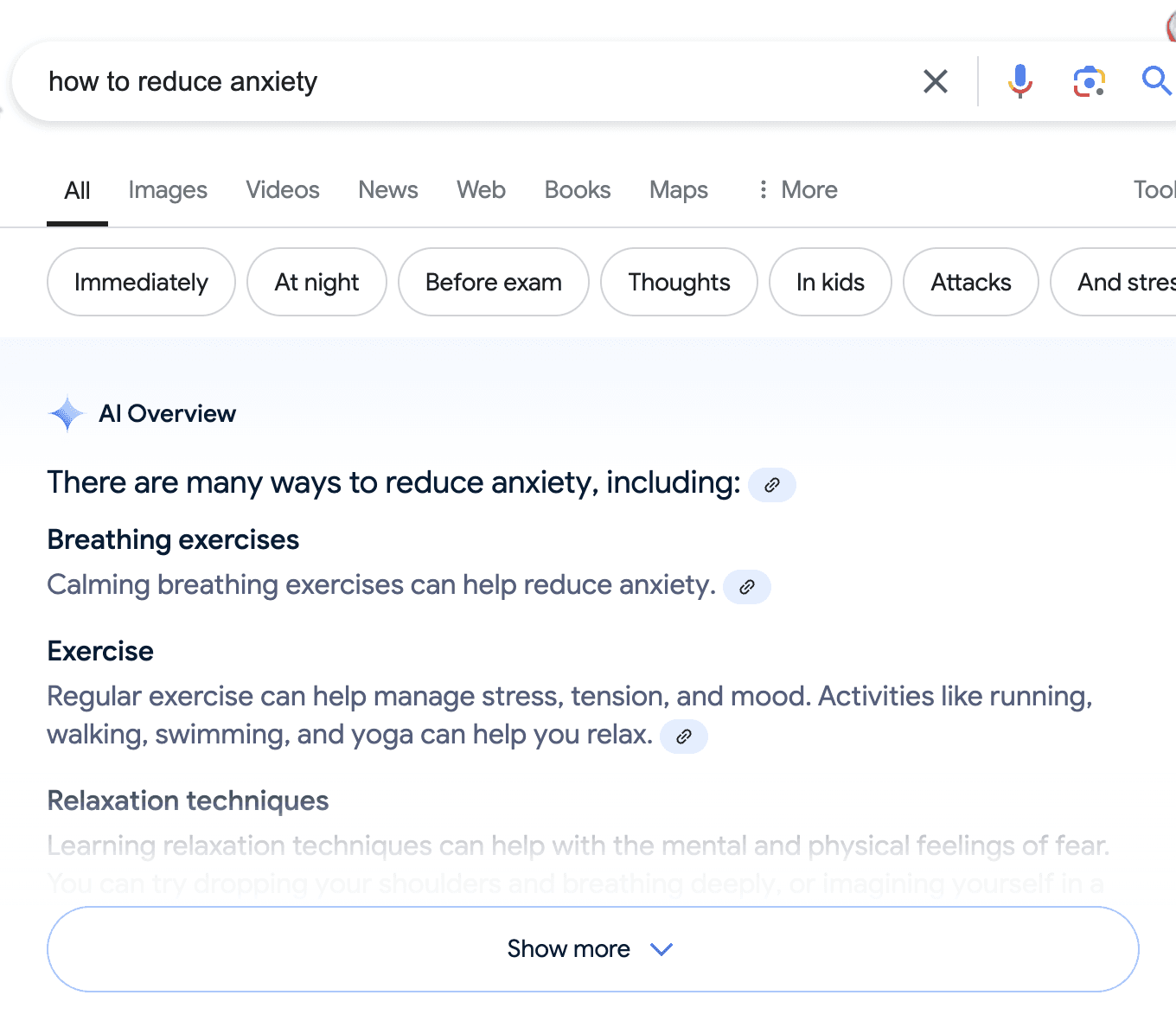
Example of One-Boxing on a Google search results for “how to reduce anxiety” Source: Google.
6. GEO (Generative Engine Optimisation)
The lines between search and chat are blurring. As mentioned above, publishers are increasingly concerned about one-boxing, and it seems to be set in stone that we are heading towards this. Generative Engine Optimisation (GEO) represents a new approach to content optimisation, aimed specifically at ensuring that a website or its content is featured in AI model-generated responses. Rather than focusing on traditional search engine rankings, GEO strategies are designed to enhance the visibility of content within generative AI systems, allowing publishers to adapt to this emerging paradigm and ensure that their material remains accessible.
7. Inference
Inference in generative AI refers to the process in which trained AI models generate responses, whether that be text, image, video, 3D, and etc. It involves applying the learned patterns, relationships, and insights from the training phase to real-world queries. For example, you give an LLM the prompt “What is London known for?”, and the model uses its pre-trained knowledge to predict the most likely sequence of words in response. Inference’s effectiveness and efficiency are essential for the practical utility of AI applications.

Example of inference in a generative AI tool. Source: ChatGPT.
8. Context Enrichment
Context enrichment involves enhancing AI model prompts at inference time by incorporating additional relevant information to generate more accurate and tailored responses. This can include user preferences, past interactions, or external data, helping the model better understand the context of a query and mitigate against hallucinations (where the mode makes stuff up). A popular technique for content enrichment is Retrieval Augmented Generation (or RAG), in which relevant information is retrieved from external databases or knowledge sources during inference and incorporates that data into its responses. By combining real-time retrieval with generative capabilities, RAG helps the model produce more accurate and contextually relevant answers, thereby reducing the likelihood of generating incorrect or fabricated information.
9. Influence Functions
It is a concept used in machine learning and statistics to understand the impact of individual training examples on a model's predictions. They help in analysing how sensitive a model is to changes or perturbations in the training data. When doing inference on an AI model, it is only able to respond as well as it does due to the quality and diversity of the data it is trained on. However, the problem of properly identifying and attributing which bits of the data were responsible for the model’s output is challenging. Influence functions are an interesting research area in explainable AI in which the specific data points used by the model in generating its output can be identified. This unlocks potential for attribution and revenue share directly back to the contributors of the training data.
The history and origin of data—including how it was collected, processed, and transformed—are crucial for understanding its provenance.
10. Data Provenance
Data provenance is a comprehensive record of the origin, history, and transformation of a dataset, ensuring its trustworthiness. Provenance provides transparency and trust by documenting who, what, and when for a dataset. In machine learning, data provenance is essential for ensuring the integrity and quality of datasets, helping address critical copyright considerations, and enabling proper attribution and compensation back to the rights holders who provide the invaluable content powering these models. At Valyu, we are dedicated to fostering trusted AI by prioritising data provenance.

Example of provenance overview of a dataset. Source: Valyu Exchange.
In Conclusion
Understanding the key terms related to AI training data is essential for grasping how AI models are built and function. From the foundational role of large language models and the importance of high-quality training data to the emerging concepts like Generative Engine Optimisation (GEO) and context enrichment, each aspect plays a critical role in the effectiveness and reliability of AI systems. Additionally, concepts such as influence functions and data provenance further emphasise the need for transparency, accuracy, and ethical considerations in AI development.
—-
Cover Image by Google DeepMind from Pexels.